论文的主题是研究如何使机器人能够理解并适应人类在实际操作中的反馈,特别是在物体中心的任务中。作者提出了一种名为"Object Preference Adaptation"(OPA)的方法,该方法包括两个关键阶段:1)预训练一个基础策略以产生各种行为,2)根据人类的反馈进行在线更新。这种方法的关键在于,它固定了代理和物体之间的一般交互动态,只更新特定于物体的偏好。这种适应是在线的,只需要一次人类的干预(一次性),并能产生在训练期间从未见过的新行为。
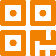
作者以一个工厂设置的例子来说明这种方法的应用。在这个例子中,一个机器人被训练来从3D打印机中取出打印的物品,然后将它们放入一个清洁箱中。然而,当制造过程突然改变时,机器人还需要将物品直立放在一个扫描器中,然后再将它们放入清洁箱中。在这种情况下,人类操作员可以通过物理纠正来快速自然地传达这种任务修改。在机器人拿起物品后,人类会引导并拖动机器人的手臂,使其朝向扫描器,并让末端执行器将物品直立放置几秒钟,然后再引导手臂朝向箱子。这种绕道可以简单地描述为一个额外的物体中心的子任务。此外,作者还指出,他们的策略在经济合算的合成数据上进行训练,而不是昂贵的人类示范。在物理7DOF机器人上,他们的策略能够正确地适应人类对实际任务的干扰。接下来主要讨论了如何从人类的行为中推断出对象中心的含义。在这个过程中,场景被表示为一个图,其中节点是机器人和所有其他对象,有向边仅从每个对象指向机器人。这种图形结构自然地让我们能够单独模型每个对象及其与机器人的关系。在时间t,设xr,t ∈ Rd代表机器人r的当前状态,xi,t ∈ Rd代表场景中其他对象i ∈ [N]的状态。这假设我们可以检测,唯一地识别,并提取场景中每个对象的6D姿态。机器人的状态根据动态xr,t+1 = xr,t + αut进行更新,其中α是一个常数步长,ut ∈ Rd'是由人类(如果可用)或者由策略生成的动作。人类的干预被记为u\nt,机器人的策略被记为ut = fO(xr,t, {xi,t}i∈[N], g),其中目标g被假定为给定的。一般的学习目标是在T步内匹配人类的动作。此外,该部分还讨论了如何通过合成数据进行训练,以及如何在测试时训练和适应策略。对于位置和方向,注意到它们的计算是完全独立的。这允许我们分别优化它们的损失LP和LR,绕过了不同单位的问题。这也允许我们使用不同的数据集来训练两个网络,这是必要的,因为这两个网络的训练数据集可能不同。
在下一部分部分作者主要讨论了如何从人类的行为中推断出对象中心的含义。在这个过程中,场景被表示为一个图,其中节点是机器人和所有其他对象,有向边仅从每个对象指向机器人。这种图形结构自然地让我们能够单独模型每个对象及其与机器人的关系。在时间t,设xr,t ∈ Rd代表机器人r的当前状态,xi,t ∈ Rd代表场景中其他对象i ∈ [N]的状态。这假设我们可以检测,唯一地识别,并提取场景中每个对象的6D姿态。机器人的状态根据动态xr,t+1 = xr,t + αut进行更新,其中α是一个常数步长,ut ∈ Rd'是由人类(如果可用)或者由策略生成的动作。人类的干预被记为u\nt,机器人的策略被记为ut = fO(xr,t, {xi,t}i∈[N], g),其中目标g被假定为给定的。一般的学习目标是在T步内匹配人类的动作。此外,该部分还讨论了如何通过合成数据进行训练,以及如何在测试时训练和适应策略。对于位置和方向,注意到它们的计算是完全独立的。这允许我们分别优化它们的损失LP和LR,绕过了不同单位的问题。这也允许我们使用不同的数据集来训练两个网络,这是必要的,因为这两个网络的训练数据集可能不同。
接着作者主要讨论了如何训练策略并在测试时进行适应。首先,由于模仿学习需要收集大量的演示,因此论文提出使用合成数据进行训练。对于位置和方向,它们的计算是完全独立的。这允许我们分别优化它们的损失LP和LR,绕过了不同单位的问题。这也允许我们使用不同的数据集来训练两个网络,这是必要的,因为这两个网络的训练数据集可能不同。论文还讨论了如何直接从状态空间中学习特征。最近的一些工作试图通过深度神经网络间接学习这些特征。这些深度IRL方法将原始状态空间作为输入,并依赖网络来学习一个能够转移到测试时间场景的好的表示。然而,给定有限的演示和高维状态空间,深度神经网络可能无法推广到新的场景。状态越高维,需要的数据就越多才能减少人类真实偏好的模糊性。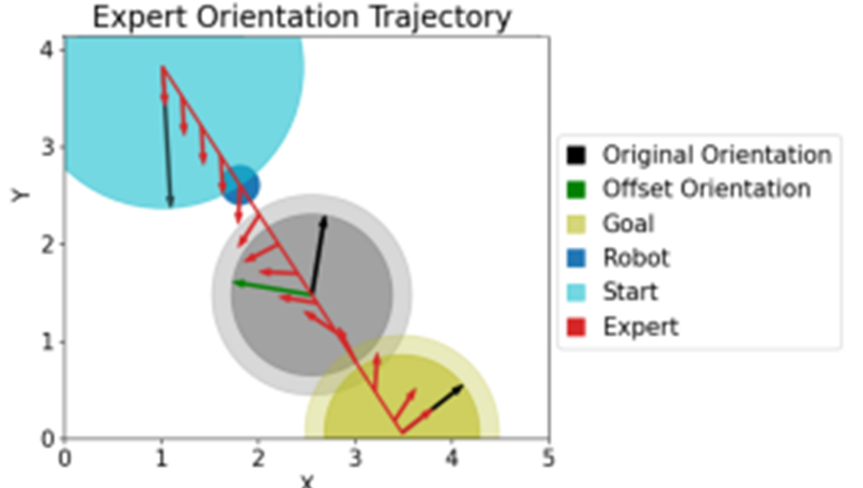
作者引用了多篇相关的研究文献,包括关于逆强化学习、人机交互、路径规划和控制等方面的研究,讨论了已经提出的一些使用人类反馈适应机器人行为的方法。例如,有些研究假设人类的意图可以被模型为预定义特征函数的线性组合。然而,这些预定义的基函数可能无法覆盖变化的人类偏好,特别是当机器人被部署到新任务时,例如在新安装的扫描器下扫描标签。更近期的一些工作试图使用深度神经网络学习这些特征,但有效的学习需要足够的数据和时间,而且可能无法推广到新的测试场景。有些研究试图使用更结构化的人类反馈来学习小型的多层感知器(MLP),但这样的简单MLP可能无法推广到新的场景。为了解决上述挑战,作者提出了对象偏好适应(OPA)方法,该方法1) 明确考虑每个对象和机器人之间的成对关系,2) 将人类反馈解释为这些关系。首先,作者预训练了一个策略,以复制遵循特定模式的随机生成的轨迹:在与附近对象交互的同时,达到目标。策略参数被分为两组:编码对象之间一般交互动态的核心权重,和对象特定的特征。作者假设只有四个可能的对象特定的特征,这使得在线适应变得简单且计算效率高。
作者提出了一种新的方法,名为对象偏好适应(OPA),该方法可以从物理反馈中推断出人类对对象的意图。OPA将环境表示为一个图,节点为对象,每个对象和代理之间的边。在预训练基础策略之后,OPA只需要在紧凑的潜在空间中优化对象特定的特征。这些方面使OPA能够快速有效地适应工厂检查任务中的真实人类反馈。1.他们的方法可以解释人类的物理反馈作为对象特定的交互,并使用图形表示这些交互,从而实现快速适应。2.他们展示了仅使用合成数据就可以训练出一种策略,该策略可以处理现实任务和非结构化的人类干扰。3.他们在真实的机器人任务中实验性地展示了对人类干扰的适应性。然而,OPA仍然有一些可以解决的限制,例如学习更复杂的行为和保证目标收敛。本文由CAAI认知系统与信息处理专委会供稿